
About Me
Hello! My name is Jacob Krantz and I build embodied artificial intelligence. I solve problems relating to task planning, navigation, 3D perception, and data scaling. I am a Member of the Technical Staff (MTS) with Amazon's Frontier AI & Robotics (FAR) lab.
Previously, I was a Senior Research Scientist at FAIR Meta on the embodied AI / robotics team (2024-2025). I received my Ph.D. in Computer Science from Oregon State University in 2023. I was advised by Dr. Stefan Lee and studied semantic embodied navigation [Dissertation]. During my Ph.D., I interned twice at FAIR; I worked with Devendra Chaplot in 2022 and Oleksandr Maksymets in 2020. Prior to Oregon State, I received my B.Sc. in Computer Science from Gonzaga University and was advised by Dr. Paul De Palma. In 2018, I was an REU Fellow at the University of Colorado, Colorado Springs advised by Dr. Jugal Kalita.
In my free time, I am an avid mountain athlete. From rock climbing, ski mountaineering, to trail running, you can find me in the mountains all year long.
recent news
| Apr, 2026 | I joined Amazon's Frontier AI & Robotics (FAR) lab as a Member of the Technical Staff (MTS). |
| Jan, 2026 | Our work building a perception memory for long-horizon robot task planning has been accepted to ICLR 2026. |
| Jun, 2025 | Our work on visual imaginations for VLN appeared at CVPR 2025. |
| Feb, 2025 | We presented PARTNR at ICLR 2025. |
| Oct, 2024 | We released PARTNR, a benchmark for planning and reasoning in multi-agent tasks [Website]. |
| Jan, 2024 | I started at FAIR as a Research Scientist in Embodied AI. |
| Nov, 2023 | I successfully defended my dissertation and received my Ph.D. from Oregon State University. |
Select Open Research
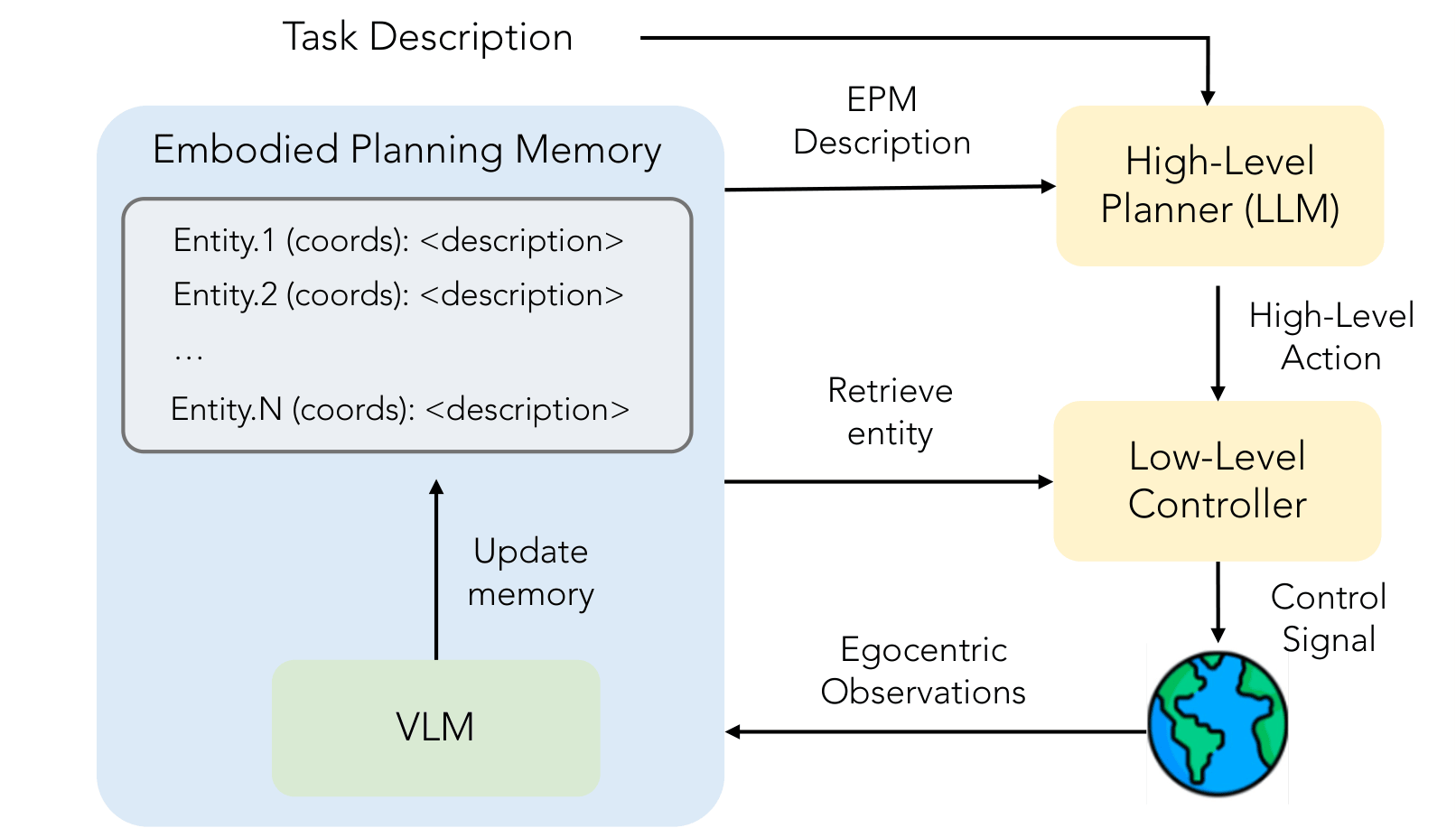
Planning with an Embodied Learnable Memory
Priyam Parashar, Jacob Krantz, Matthew Chang, Xavier Puig, Roozbeh Mottaghi
ICLR, 2026
We develop a novel memory representation for embodied planning models performing long-horizon mobile manipulation in dynamic, large-scale indoor environments. Prior memory representations fall short in this setting, as they struggle with object movements, suffer from computational deficiencies, and often depend on the heuristic integration of multiple models. To overcome these limitations, we present the Embodied Perception Memory (EPM), a learnable memory designed for embodied planning. EPM is implemented as a unified Vision-Language Model (VLM) that uses egocentric vision to maintain and update a textual environment representation. We further introduce two complementary methods for training planners to leverage the EPM: an imitation strategy that uses human trajectories for natural exploration and interaction, and a novel reinforcement learning approach, Dynamic Difficulty-Aware Fine-Tuning (DDAFT), which improves planning performance via difficulty-aware exploration. Our memory representation, when integrated with our planning training methods, leads to significant improvements on planning tasks, showing up to a 55% increase in success rate on the PARTNR benchmark compared to strong baselines. Also, our planning method outperforms these baselines even when they have access to groundtruth perception.

PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
(alphabetical order) Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, Siddharth Patki, Ishita Prasad, Xavier Puig, Akshara Rai, Ram Ramrakhya, Daniel Tran, Joanne Truong, John M. Turner, Eric Undersander, Tsung-Yen Yang
ICLR, 2025
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
Paper | Bibtex | Press Release | Website | Code
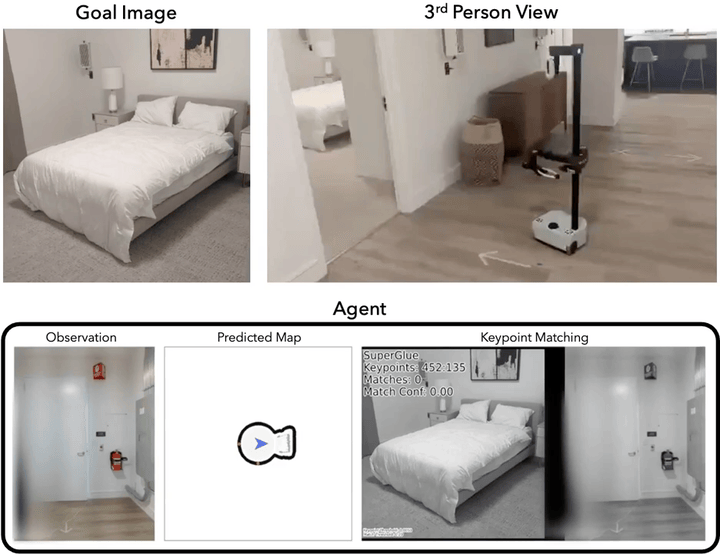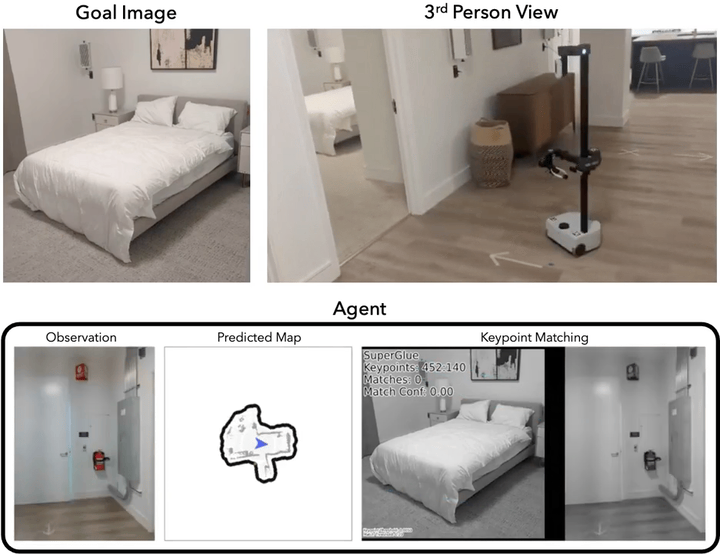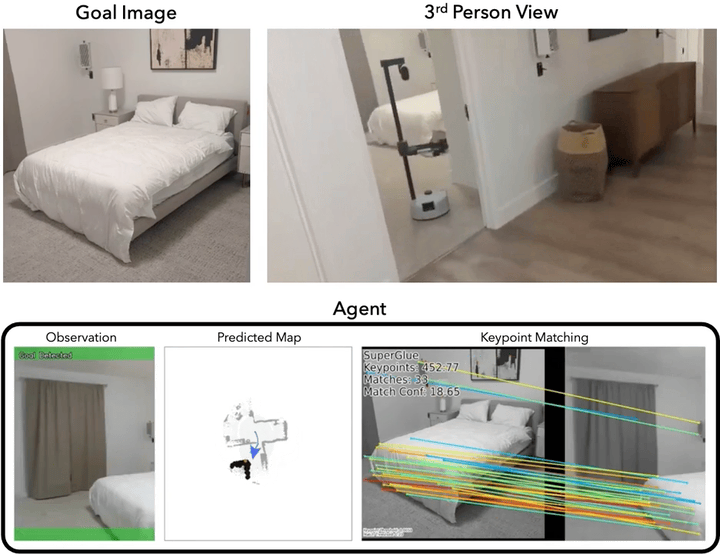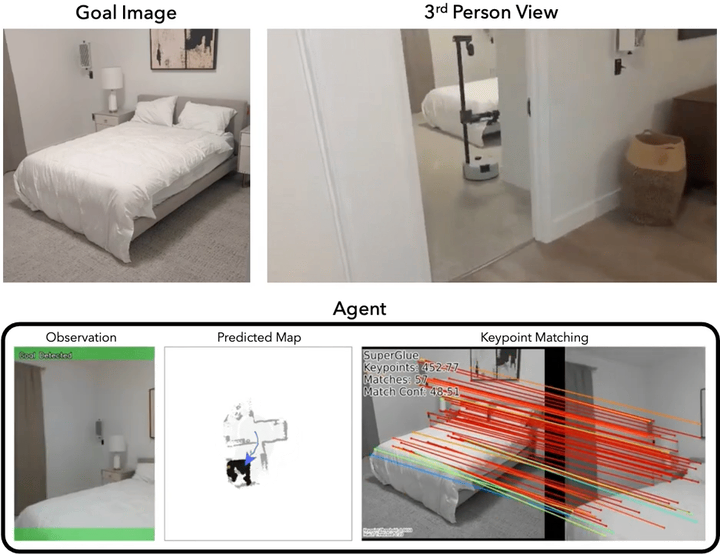
Navigating to Objects Specified by Images
Jacob Krantz
Theophile Gervet
Karmesh Yadav
Austin Wang
Chris Paxton
Roozbeh Mottaghi
Dhruv Batra
Jitendra Malik
Stefan Lee
Devendra Singh Chaplot
ICCV, 2023
Images are a convenient way to specify which particular object instance an embodied agent should navigate to. Solving this task requires semantic visual reasoning and exploration of unknown environments. We present a system that can perform this task in both simulation and the real world. Our modular method solves sub-tasks of exploration, goal instance re-identification, goal localization, and local navigation. We re-identify the goal instance in egocentric vision using feature-matching and localize the goal instance by projecting matched features to a map. Each sub-task is solved using off-the-shelf components requiring zero fine-tuning. On the HM3D InstanceImageNav benchmark, this system outperforms a baseline end-to-end RL policy 7x and a state-of-the-art ImageNav model 2.3x (56% vs. 25% success). We deploy this system to a mobile robot platform and demonstrate effective real-world performance, achieving an 88% success rate across a home and an office environment.
Iterative Vision-and-Language Navigation
Jacob Krantz*
Shurjo Banerjee*
Wang Zhu
Jason Corso
Peter Anderson
Stefan Lee
Jesse Thomason
CVPR, 2023
We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
Paper | Bibtex | Website | IVLN Code | IVLN-CE Code
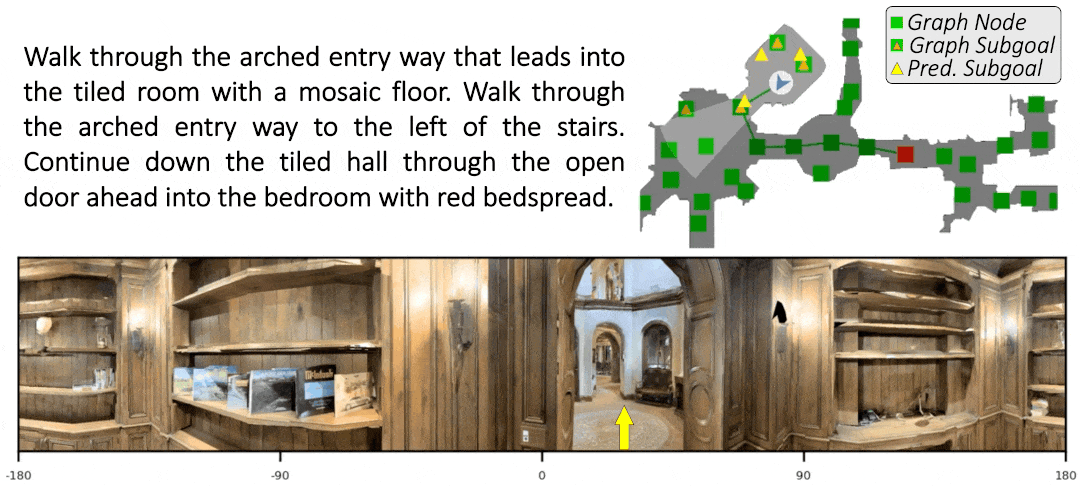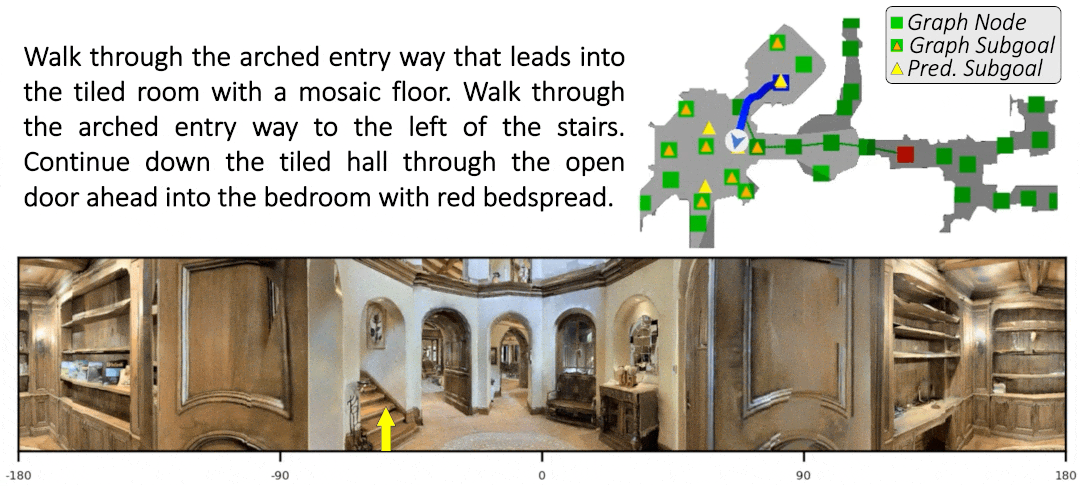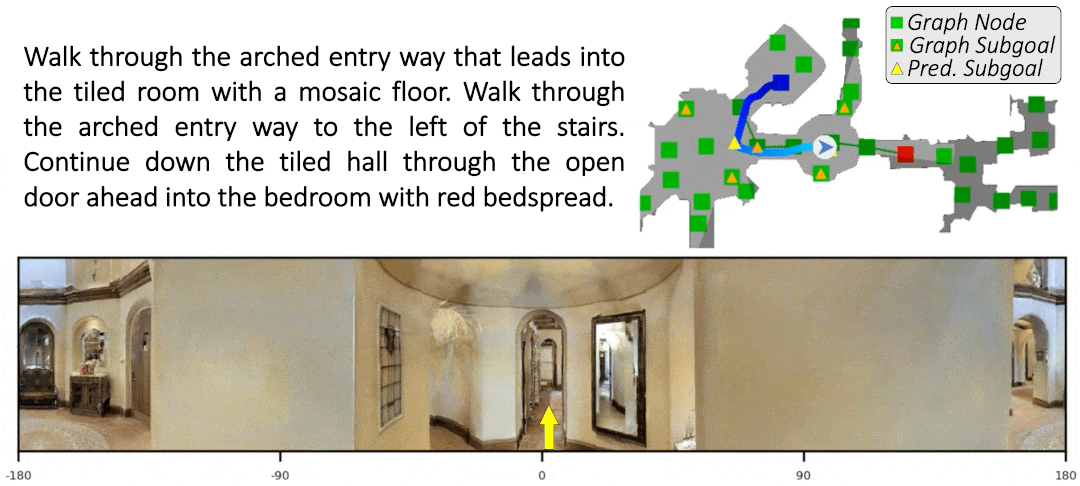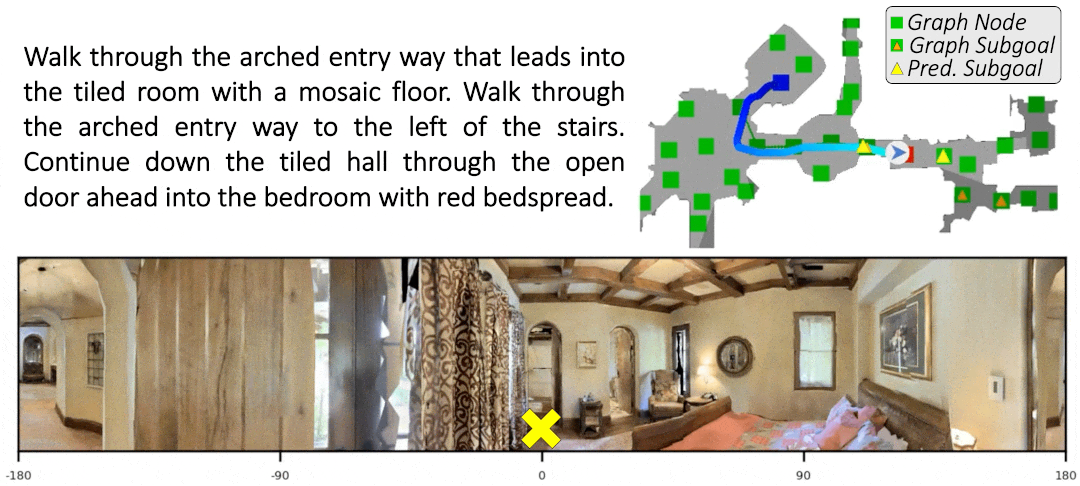
Sim-2-Sim Transfer for Vision-and-Language Navigation in Continuous Environments
Jacob Krantz Stefan Lee
ECCV, 2022 (Oral: 2.7%)
Recent work in Vision-and-Language Navigation (VLN) has presented two environmental paradigms with differing realism -- the standard VLN setting built on topological environments where navigation is abstracted away, and the VLN-CE setting where agents must navigate continuous 3D environments using low-level actions. Despite sharing the high-level task and even the underlying instruction-path data, performance on VLN-CE lags behind VLN significantly. In this work, we explore this gap by transferring an agent from the abstract environment of VLN to the continuous environment of VLN-CE. We find that this sim-2-sim transfer is highly effective, improving over the prior state of the art in VLN-CE by +12% success rate. While this demonstrates the potential for this direction, the transfer does not fully retain the original performance of the agent in the abstract setting. We present a sequence of experiments to identify what differences result in performance degradation, providing clear directions for further improvement.
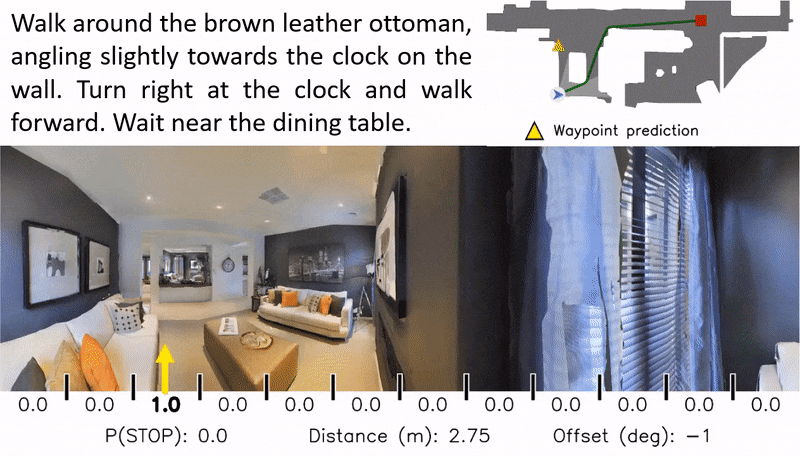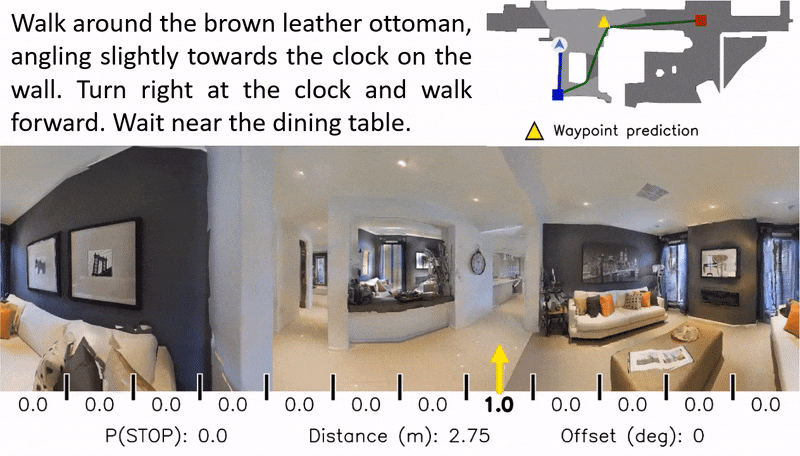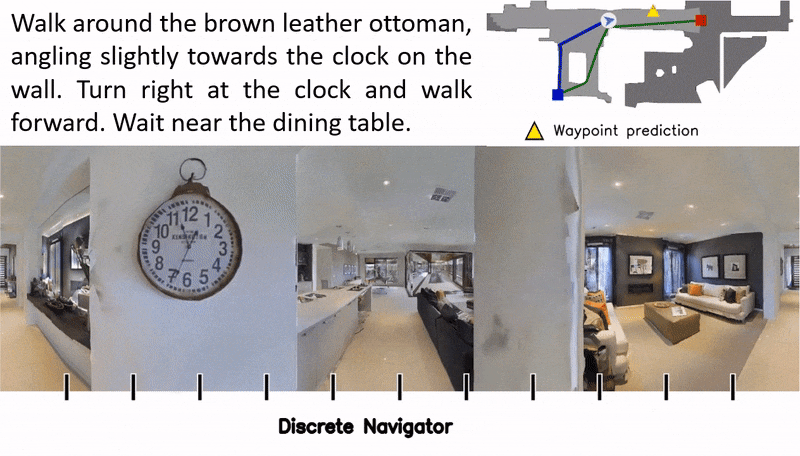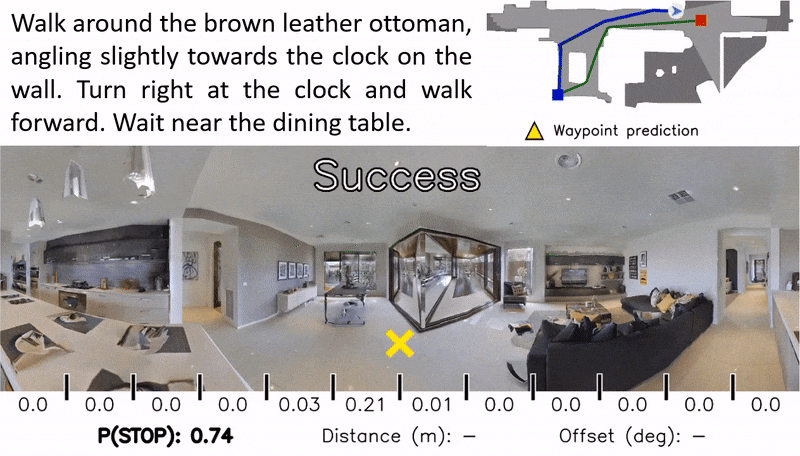
Waypoint Models for Instruction-guided Navigation in Continuous Environments
Jacob Krantz Aaron Gokaslan Dhruv Batra Stefan Lee Oleksandr Maksymets
ICCV, 2021 (Oral: 3.3%)
Little inquiry has explicitly addressed the role of action spaces in language-guided visual navigation – either in terms of its effect on navigation success or the efficiency with which a robotic agent could execute the resulting trajectory. Building on the recently released VLN-CE setting for instruction following in continuous environments, we develop a class of language-conditioned waypoint prediction networks to examine this question. We vary the expressivity of these models to explore a spectrum between low-level actions and continuous waypoint prediction. We measure task performance and estimated execution time on a profiled LoCoBot robot. We find more expressive models result in simpler, faster to execute trajectories, but lower-level actions can achieve better navigation metrics by approximating shortest paths better. Further, our models outperform prior work in VLN-CE and set a new state-of-the-art on the public leaderboard – increasing success rate by 4% with our best model on this challenging task.
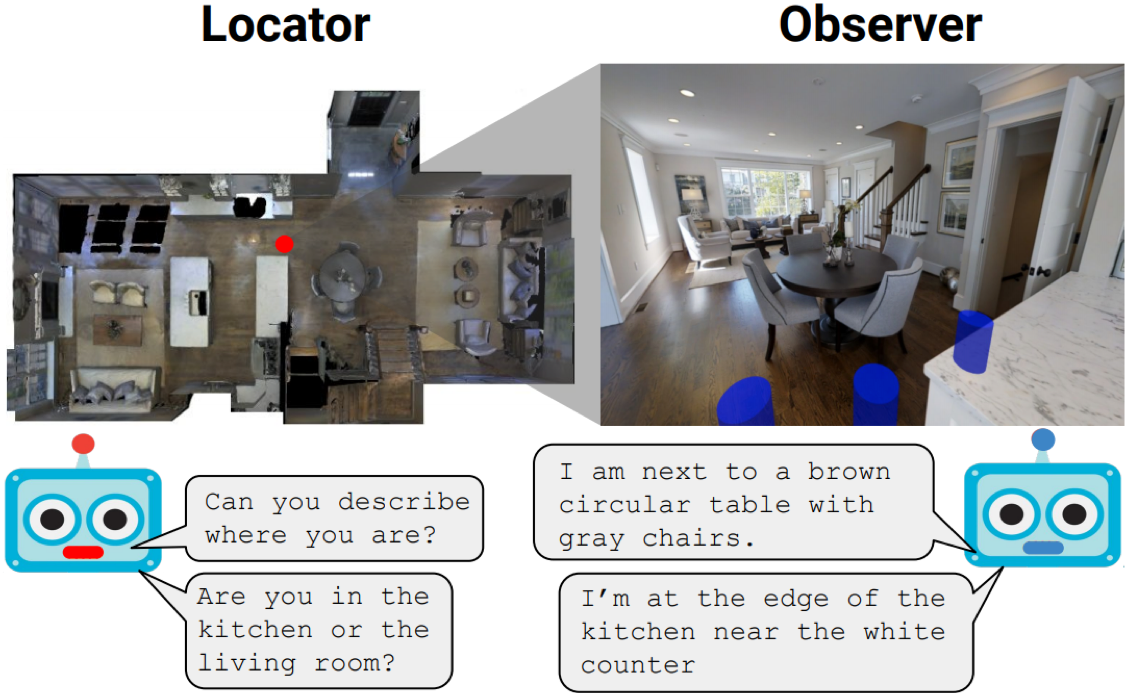
Where Are You? Localization from Embodied Dialog
Meera Hahn Jacob Krantz Dhruv Batra Devi Parikh James M. Rehg
EMNLP, 2020
We present WHERE ARE YOU? (WAY), a dataset of ∼6k dialogs in which two humans – an Observer and a Locator – complete a cooperative localization task. The Observer is spawned at random in a 3D environment and can navigate from first-person views while answering questions from the Locator. The Locator must localize the Observer in a detailed top-down map by asking questions and giving instructions. Based on this dataset, we define three challenging tasks: Localization from Embodied Dialog or LED (localizing the Observer from dialog history), Embodied Visual Dialog (modeling the Observer), and Cooperative Localization (modeling both agents). In this paper, we focus on the LED task – providing a strong baseline model with detailed ablations characterizing both dataset biases and the importance of various modeling choices. Our best model achieves 32.7% success at identifying the Observer’s location within 3m in unseen buildings, vs. 70.4% for human Locators.

Beyond the Nav-Graph: Vision and Language Navigation in Continuous Environments
Jacob Krantz Erik Wijmans Arjun Majundar Dhruv Batra Stefan Lee
ECCV, 2020
We develop a language-guided navigation task set in a continuous 3D environment where agents must execute low-level actions to follow natural language navigation directions. By being situated in continuous environments, this setting lifts a number of assumptions implicit in prior work that represents environments as a sparse graph of panoramas with edges corresponding to navigability. Specifically, our setting drops the presumptions of known environment topologies, short-range oracle navigation, and perfect agent localization. To contextualize this new task, we develop models that mirror many of the advances made in prior setting as well as single-modality baselines. While some of these techniques transfer, we find significantly lower absolute performance in the continuous setting – suggesting that performance in prior navigation-graph settings may be inflated by the strong implicit assumptions.
Paper | Bibtex | Website | Code | Press Coverage
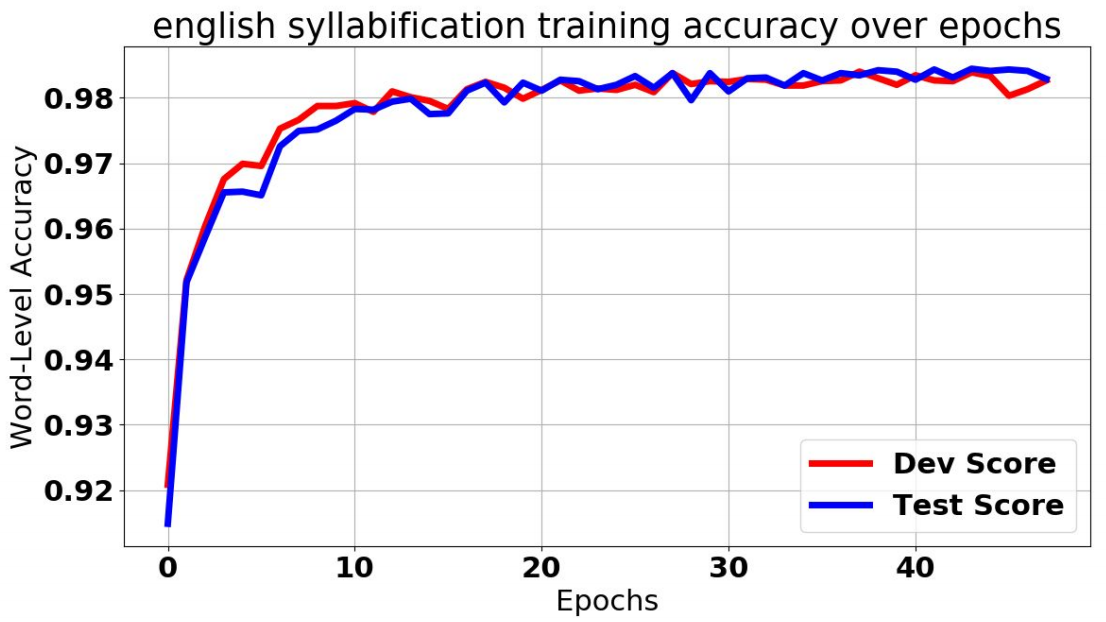
Language-Agnostic Syllabification with Neural Sequence Labeling
Jacob Krantz Maxwell Dulin Paul De Palma
IEEE International Conference on Machine Learning and Applications, 2019
The identification of syllables within phonetic sequences is known as syllabification. This task is thought to play an important role in natural language understanding, speech production, and the development of speech recognition systems. The concept of the syllable is cross-linguistic, though formal definitions are rarely agreed upon, even within a language. In response, data-driven syllabification methods have been developed to learn from syllabified examples. These methods often employ classical machine learning sequence labeling models. In recent years, recurrence-based neural networks have been shown to perform increasingly well for sequence labeling tasks such as named entity recognition (NER), part of speech (POS) tagging, and chunking. We present a novel approach to the syllabification problem which leverages modern neural network techniques. Our network is constructed with long short-term memory (LSTM) cells, a convolutional component, and a conditional random field (CRF) output layer. Existing syllabification approaches are rarely evaluated across multiple language families. To demonstrate cross-linguistic generalizability, we show that the network is competitive with state of the art systems in syllabifying English, Dutch, Italian, French, Manipuri, and Basque datasets.
Abstractive Summarization Using Attentive Neural Techniques
Jacob Krantz Jugal Kalita
International Conference on Natural Language Processing, 2018
In a world of proliferating data, the ability to rapidly summarize text is growing in importance. Automatic summarization of text can be thought of as a sequence to sequence problem. Another area of natural language processing that solves a sequence to sequence problem is machine translation, which is rapidly evolving due to the development of attention-based encoder-decoder networks. This work applies these modern techniques to abstractive summarization. We perform analysis on various attention mechanisms for summarization with the goal of developing an approach and architecture aimed at improving the state of the art. In particular, we modify and optimize a translation model with self-attention for generating abstractive sentence summaries. The effectiveness of this base model along with attention variants is compared and analyzed in the context of standardized evaluation sets and test metrics. However, we show that these metrics are limited in their ability to effectively score abstractive summaries, and propose a new approach based on the intuition that an abstractive model requires an abstractive evaluation.
Paper | Bibtex | Model Code | Metric Code | Slides
Press Coverage
TechCrunch article on how the PARTNR work from FAIR Robotics pushes forward human-robot collaboration research.

Venture Beat article introducing our work to bring Vision and Language Navigation closer to reality via continuous environments (VLN-CE).