Navigating to Objects Specified by Images
Chris Paxton3 Roozbeh Mottaghi3,4 Dhruv Batra3,5 Jitendra Malik3,6
Stefan Lee1 Devendra Singh Chaplot3
Images are a convenient way to specify which particular object instance an embodied agent should navigate to. Solving this task requires semantic visual reasoning and exploration of unknown environments. We present a system that can perform this task in both simulation and the real world. Our modular method solves sub-tasks of exploration, goal instance re-identification, goal localization, and local navigation. We re-identify the goal instance in egocentric vision using feature-matching and localize the goal instance by projecting matched features to a map. Each sub-task is solved using off-the-shelf components requiring zero fine-tuning. On the HM3D InstanceImageNav benchmark, this system outperforms a baseline end-to-end RL policy 7x and a state-of-the-art ImageNav model 2.3x (56% vs. 25% success). We deploy this system to a mobile robot platform and demonstrate effective real-world performance, achieving an 88% success rate across a home and an office environment.
Mod-IIN: A Modular Method
We decompose InstanceImageNav into subtasks: explore the environment to find a view of the goal object (Exploration), detect the goal object in egocentric vision (Instance Re-Identification), localize the goal object in the world (Goal Localization), and navigate to it (Local Navigation).
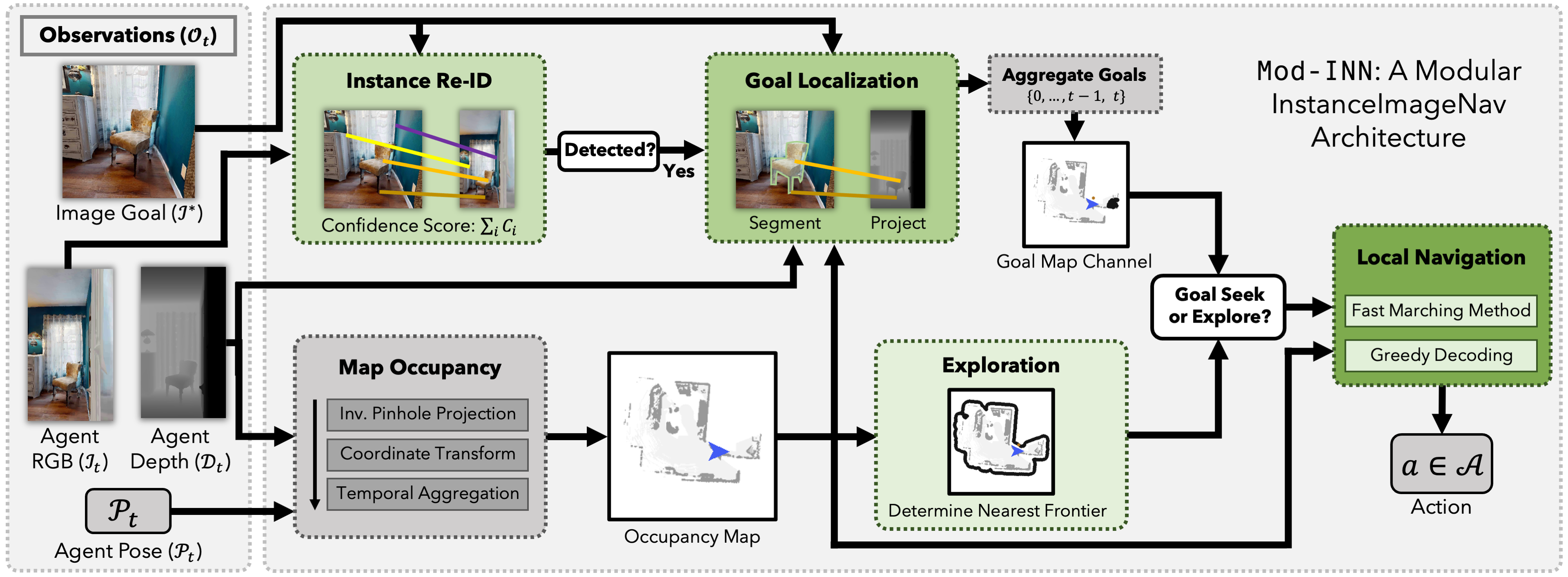
These subtasks can be solved entirely using off-the-shelf components with no task-specific fine-tuning or retraining. We employ frontier-based exploration (FBE) for exploration, feature matching for instance Re-ID, projection of feature correspondences for goal localization, and analytical planning for local navigation. We use the resulting system (Mod-IIN) to study how far we can push Image Goal Navigation in both simulation and reality using a purely modular system with off-the-shelf components.
Simulation Results
We evaluate Mod-IIN on the Habitat-Matterport3D (HM3D) benchmark for InstanceImageNav as proposed in this paper. Specifically, we use the dataset generated for the ImageNav track of the 2023 Habitat Navigation Challenge.
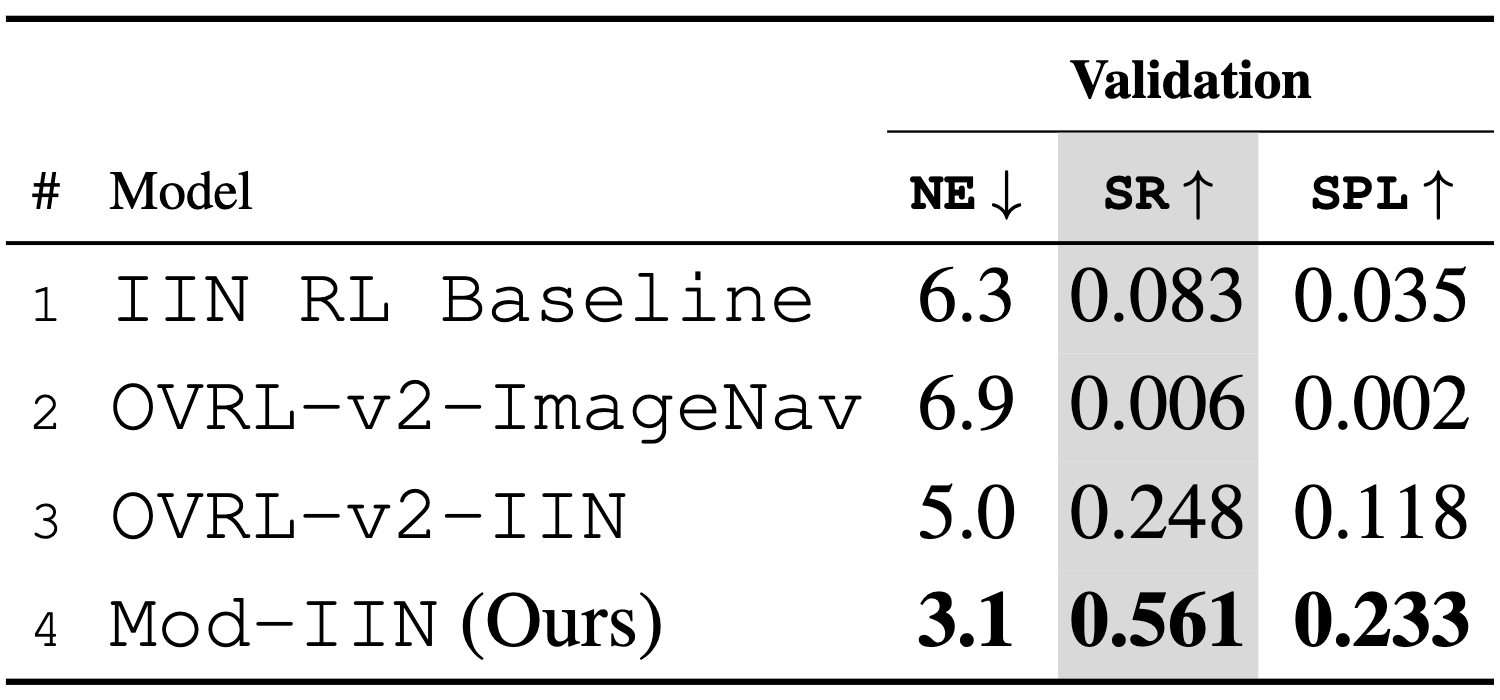
Row 1 is a sensors-to-actions policy trained from scratch for InstanceImageNav here. Row 2 is a state-of-the-art ImageNav policy with self-supervised visual pre-training (OVRL-v2) eavluated zero-shot on InstanceImageNav. Row 3 trains OVRL-v2 specifically for InstanceImageNav. Mod-IIN outperforms these learned methods significantly with higher success than the baseline (nearly 7x), and OVRL-v2 (more than 2x).
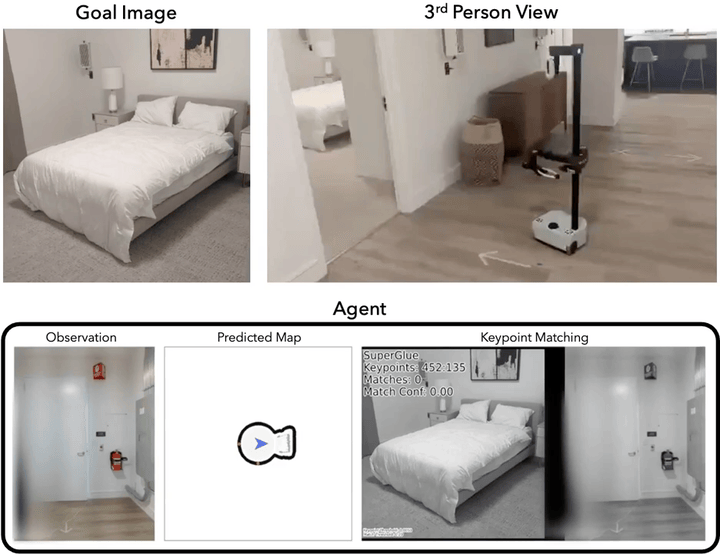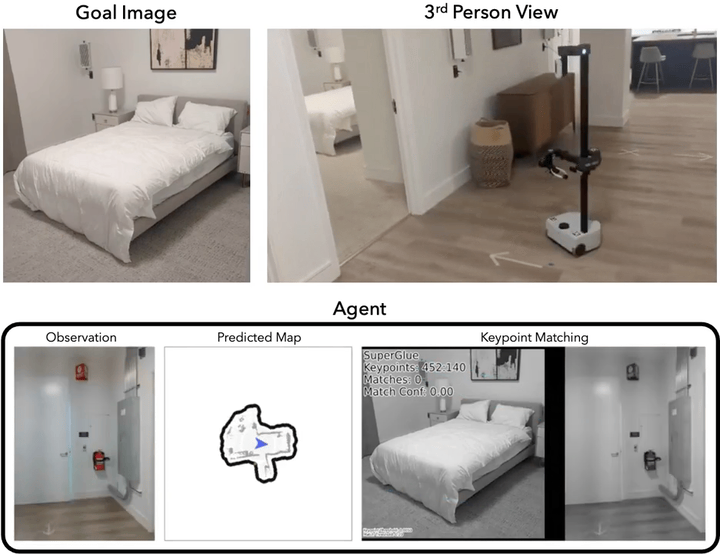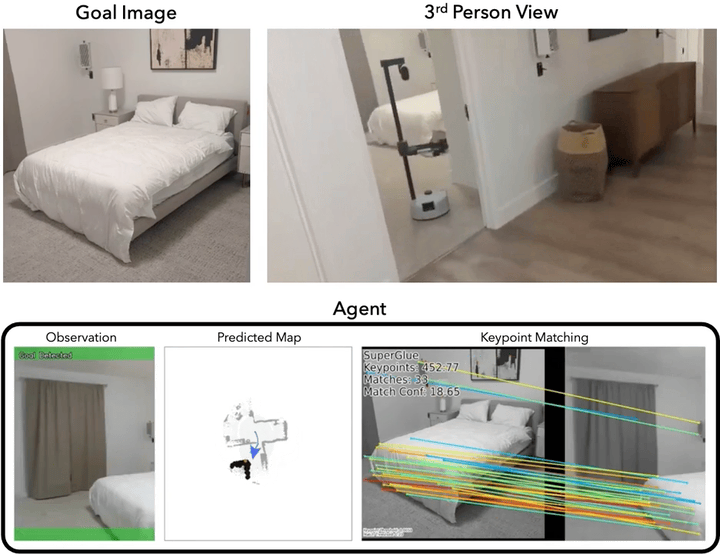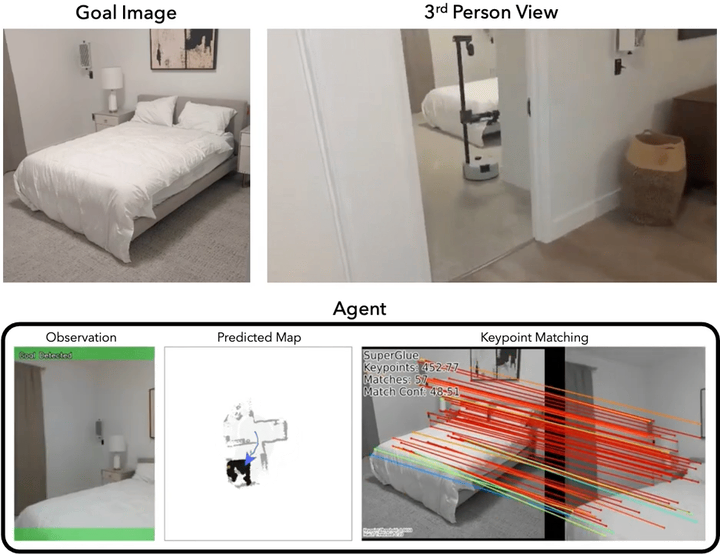
Mod-IIN in the Real World

We demonstrate that our agent performs reliably in both simulation and the real world. Here, we deploy our agent using the Hello Robot Stretch platform and experiment in two environments: a furnished office space (Env A) and a furnished apartment (Env B). Mod-IIN is successful in 7/8 episodes (88%). We show one example below. For videos of all episodes, please see this page.
Summary Video
Paper

Acknowledgements
The Oregon State effort is supported in part by the DARPA Machine Common Sense program. The views and conclusions contained herein are those of the authors and should not be interpreted as representing the official policies or endorsements, either expressed or implied, of the US Government or any sponsor.
Email — krantzja@oregonstate.edu