Iterative Vision-and-Language Navigation
Peter Anderson4 Stefan Lee1 Jesse Thomason3
We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
In IVLN, agents are given language instructions corresponding to a sequence of paths that form a tour around a 3D scene. After attempting to follow each instruction, the agent is navigated by an oracle to the correct goal location, then to the start of the next path where the next instruction is issued. Unlike conventional episodic paradigms, the agent retains memory between episodes. We establish IVLN in both the discrete Room-to-Room setting (R2R) and in the continuous Room-to-Room setting (R2R-CE), forming the IR2R and IR2R-CE benchmarks, respectively.
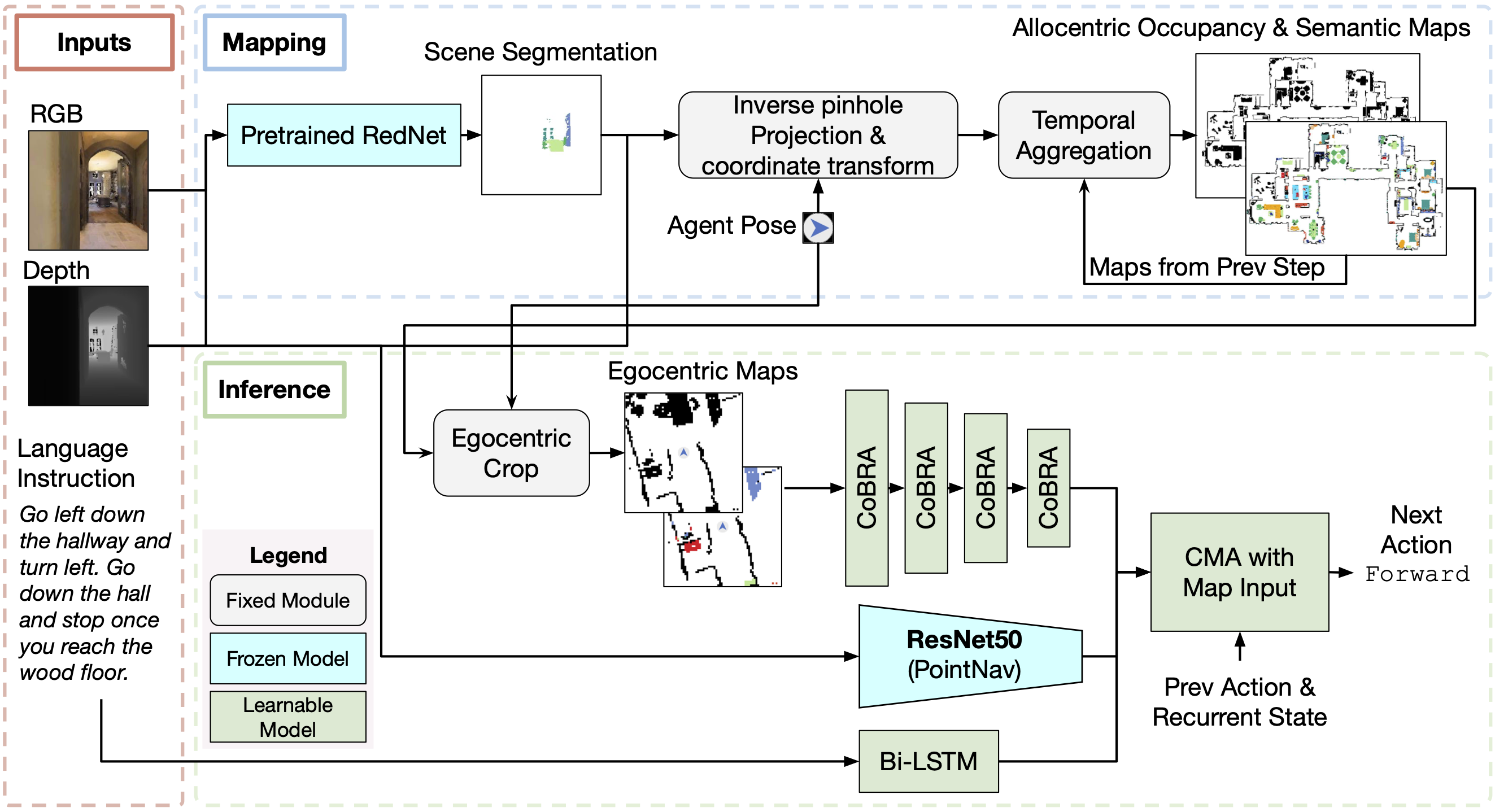
We develop and evaluate baseline agents that use unstructured memory typical in the vision-and-language navigation space. We find that these methods fail to generalize to the long and rich visuo-linguistic history of IVLN tours. However, we find that explicit semantic spatial maps enable agents to perform better during tours than in independent episodes. We develop the MapCMA model (shown below) to construct such maps throughout a tour and call upon them for instruction-following decision making.
Presentation Video
Demonstration Video
Paper

Acknowledgements
The Oregon State effort is supported in part by the DARPA Machine Common Sense program. The University of Michigan effort is supported in part by the NSF COVE (Computer Vision Exchange for Data, Annotations and Tools) initiative under Grant 1628987 and Google. Wang is supported by various corporate gifts from Google, Facebook, Netflix, Intel and Tencent. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the U.S. Government, or any sponsor.
Email — krantzja@oregonstate.edu