


Vision and Language Navigation in Continuous Environments

Vision and Language Navigation in Continuous Environments (VLN-CE) is an instruction-guided navigation task with crowdsourced instructions, realistic environments, and unconstrained agent navigation. The agent is given first-person (egocentric) vision and a human-generated instruction, such as "Go down the hall and turn left at the wooden desk. Continue until you reach the kitchen and then stop by the kettle". Using this input alone, the agent must take control actions (e.g. MOVE-FORWARD 0.25m, TURN-LEFT 15 degrees) to navigate to the goal. VLN-CE lifts assumptions of the original VLN task and aims to bring simulated agents closer to reality.

The VLN-CE codebase and baseline models are available at:
github.com/jacobkrantz/VLN-CE
The test server and leaderboard is live on EvalAI:
eval.ai/web/challenges/challenge-page/719
Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments

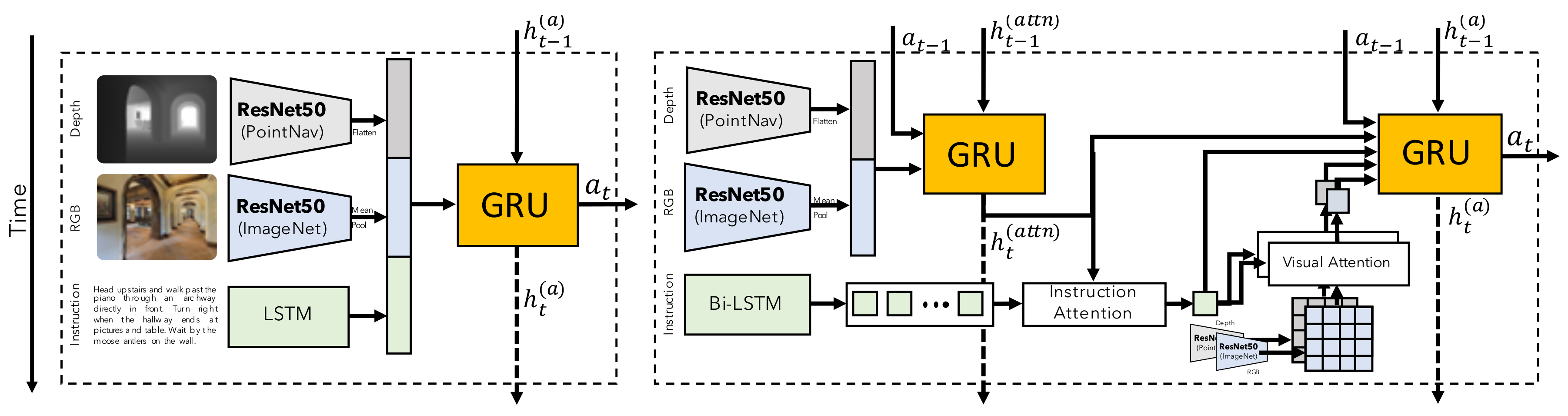
Video Examples
People





Acknowledgements
We thank Anand Koshy for his implementation of the dynamic time warping metric. The Georgia Tech effort was supported in part by NSF, AFRL, DARPA, ONR YIPs, ARO PECASE, Amazon. The Oregon State effort was supported in part by DARPA. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the U.S. Government, or any sponsor.